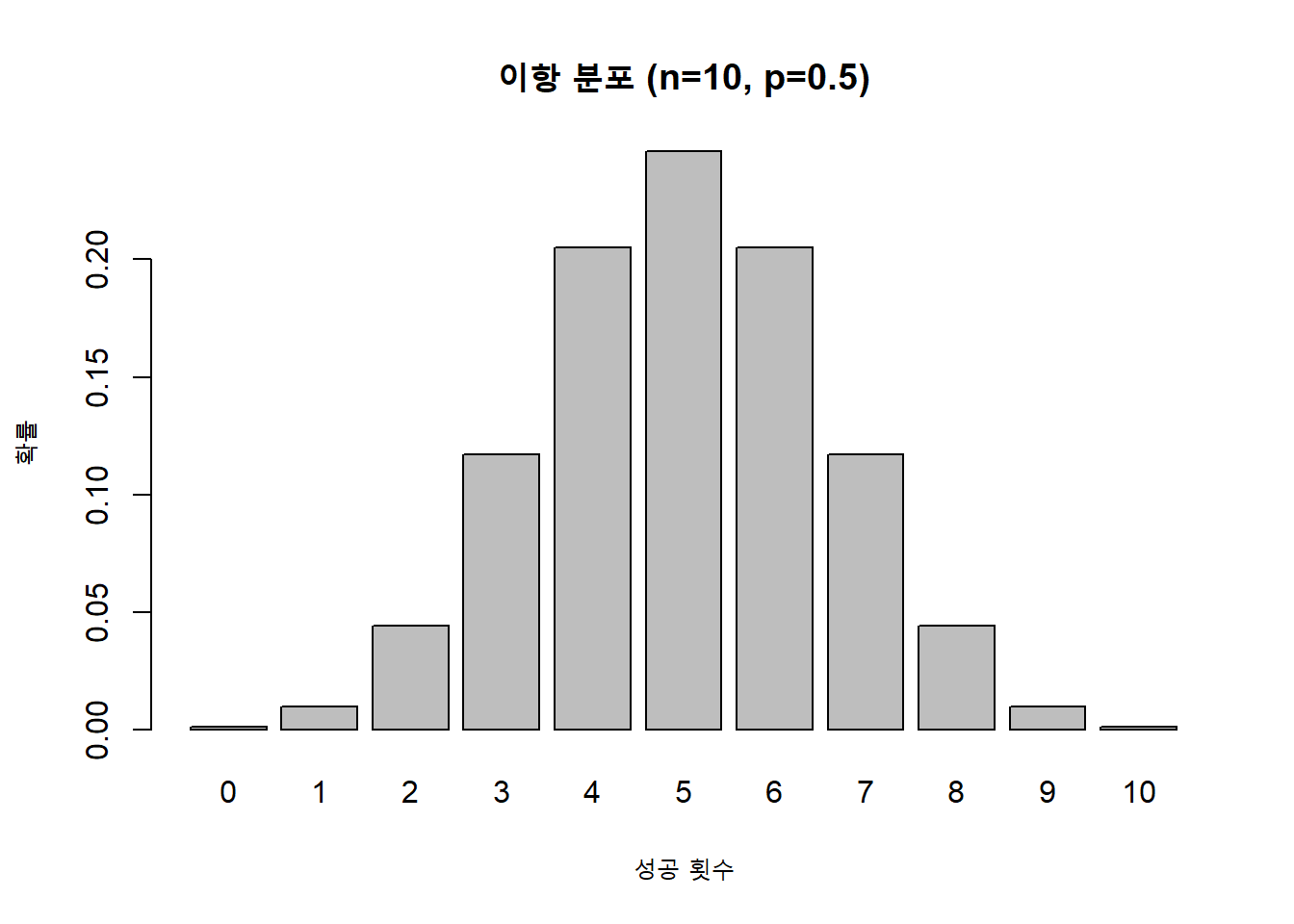
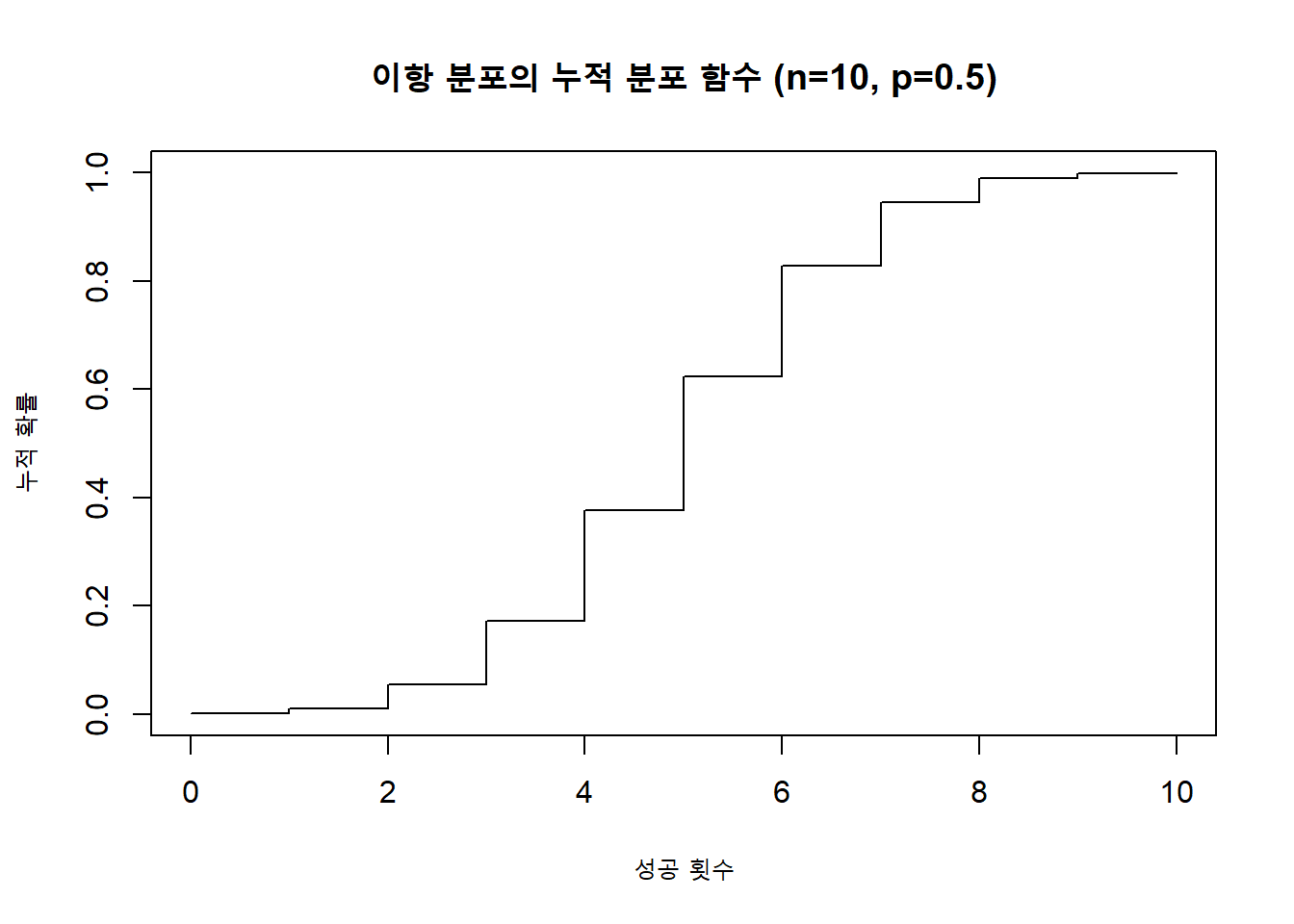
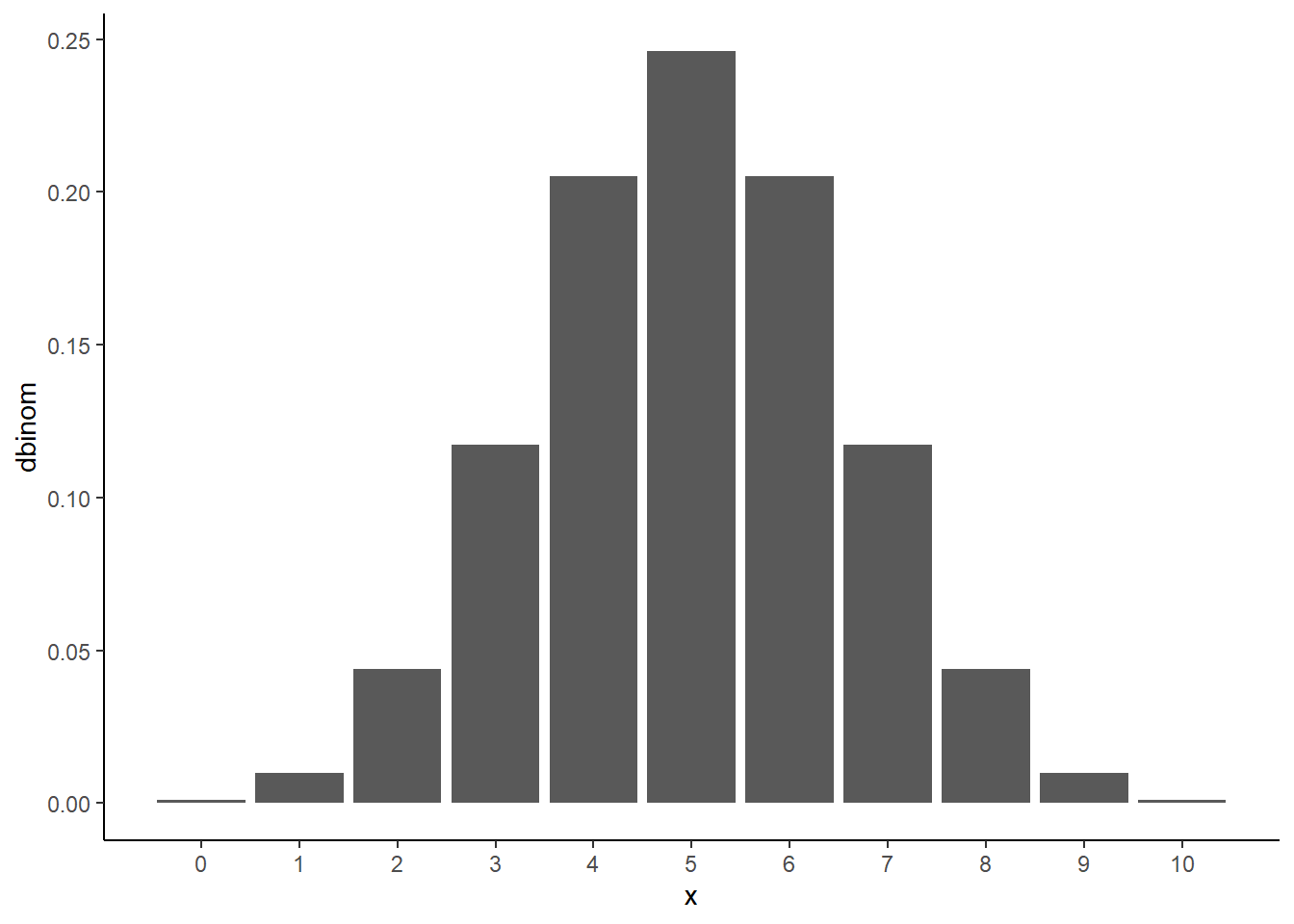
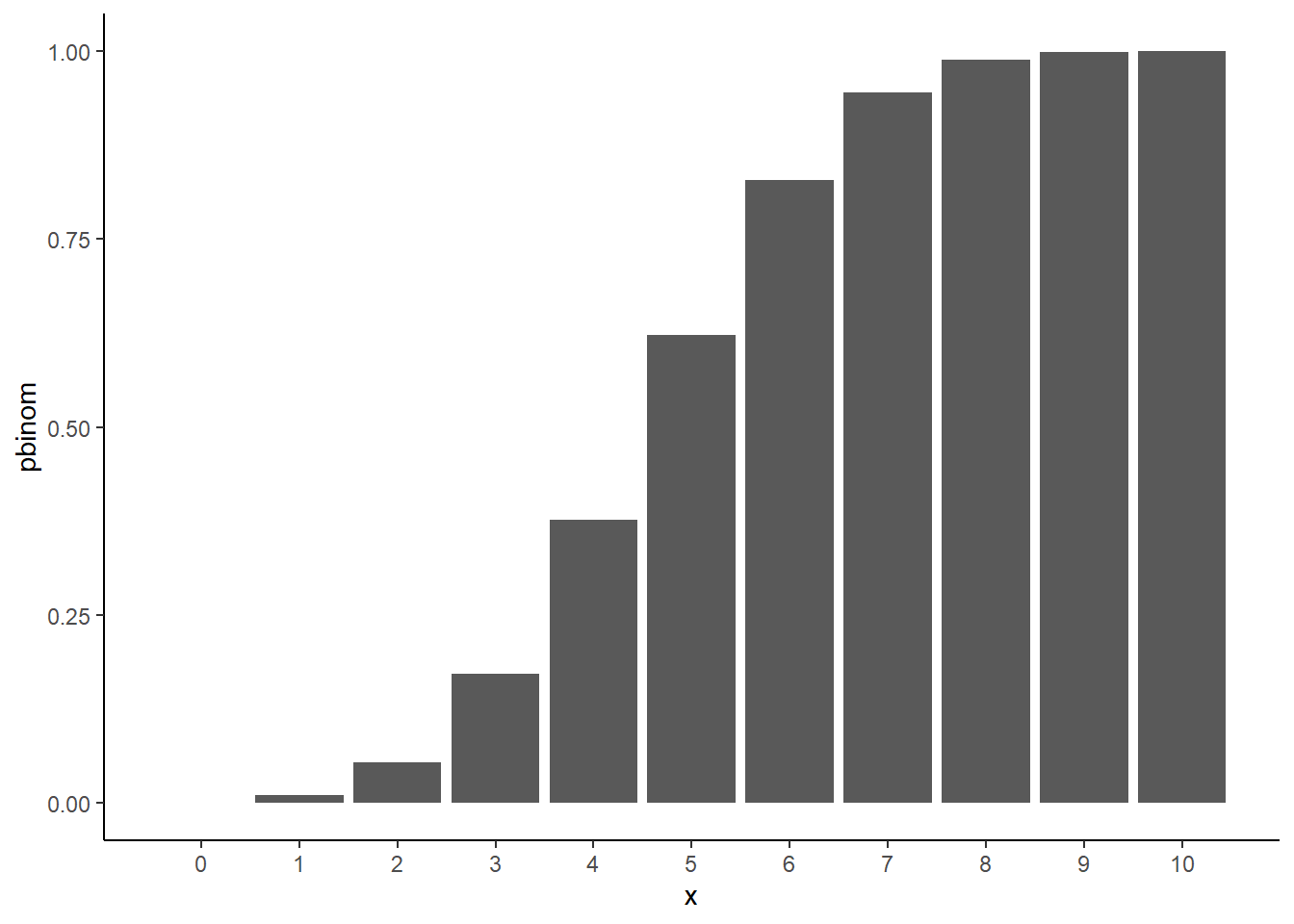
x1 <- rbind( 0, 1, 2, 3, 4, 5)
freq <- rbind(54, 117, 72, 42, 12, 3)
total <- function(x,y){
fx=y/sum(y)
cdf=cumsum(fx)
prob=sum(fx)
xfx=x*fx
mean=sum(xfx)
x2fx=x^2*fx
mix=(x-1.5)^2*fx
variance=sum(mix)
s.d=sqrt(variance)
cat( " <x> 0 1 2 3 4 5 ", "\n",
"<f(x)> ",fx,"\n",
"<F(x)> ",cdf,"\n",
"<x*f(x)> ",xfx,"\n",
"<x^2*f(x)> ",x2fx,"\n",
"<(x-1.5)^2*f(x)>",mix,"\n","\n",
"<sum(f(x))> ",prob,"\n",
"<E(x)> ",mean,"\n",
"<V(x)> ",variance,"\n",
"<S(x)> ",s.d,"\n")
}
total(x1, freq) <x> 0 1 2 3 4 5
<f(x)> 0.18 0.39 0.24 0.14 0.04 0.01
<F(x)> 0.18 0.57 0.81 0.95 0.99 1
<x*f(x)> 0 0.39 0.48 0.42 0.16 0.05
<x^2*f(x)> 0 0.39 0.96 1.26 0.64 0.25
<(x-1.5)^2*f(x)> 0.405 0.0975 0.06 0.315 0.25 0.1225
<sum(f(x))> 1
<E(x)> 1.5
<V(x)> 1.25
<S(x)> 1.118034