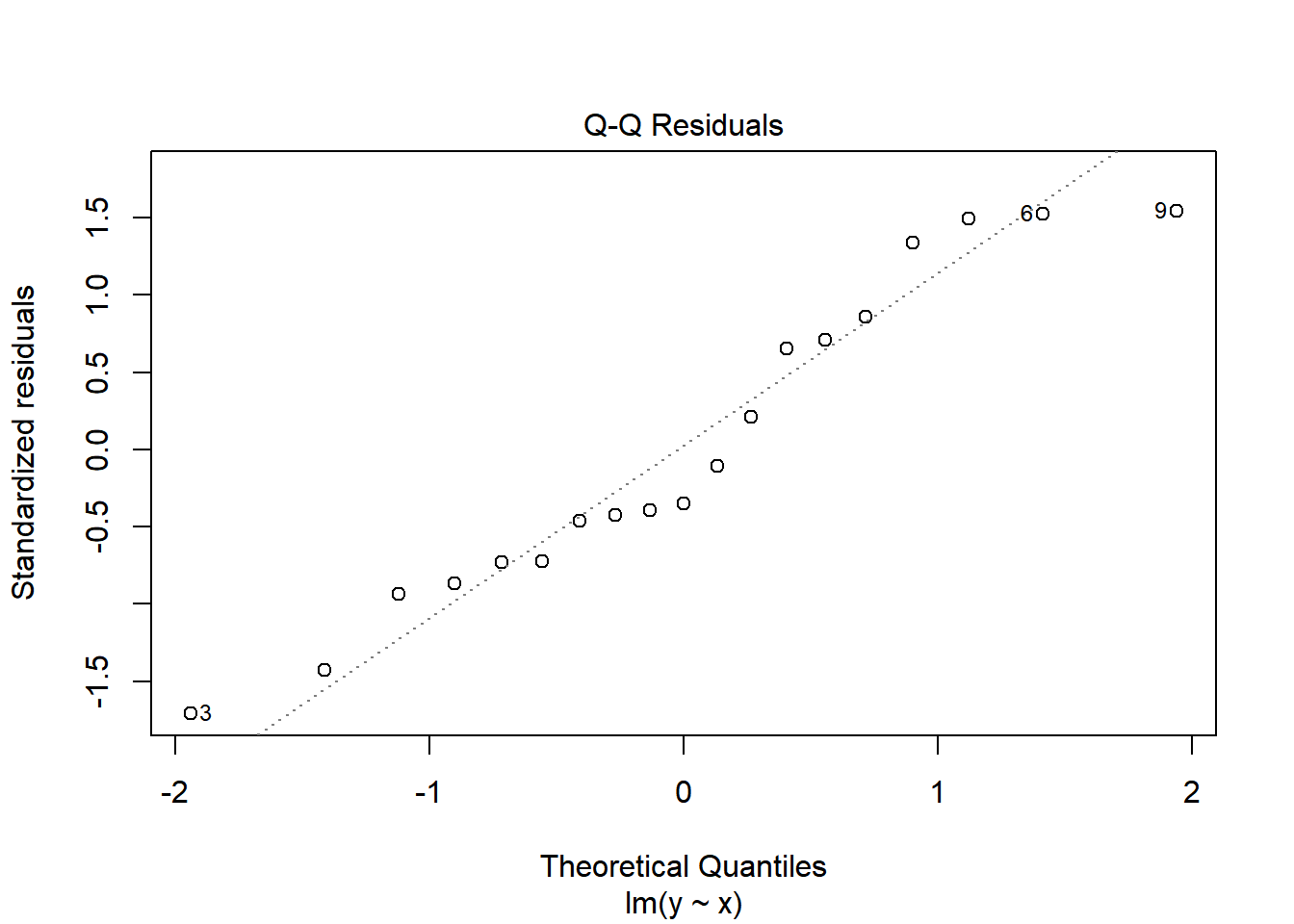국민총생산에 영향을 주는 것이 이자율 이외에 수출, 수입, R&D비율, 실업률 등 여러가지일 수 있다. 몸무게를 설명할 수 있는 변수가 키뿐 아니라 하루 칼로리 섭취량과 운동량도 영향을 줄 것이라고 생각한다면 키, 칼로리 섭취량과 운동량을 동시에 고려하여 선형회귀분석을 시도할 수 있다. 이와 같이 둘 이상의 설명변수를 고려하는 것을 다중선형회귀분석이라고 한다.
단순선형회귀분석(Simple Linear Regression)이란 종속변수와 이에 영향을 주는 독립변수가 하나인 분석이다. 독립변수와 종속변수가 모두 수치형 변수이어야 한다. 그런데 범주형 독립변수의 경우 더미변수로 만들어 사용 가능하다. 회귀모형(regression model)은 하나의 종속변수를 여러 개의 독립변수가 설명한다고 보는 통계적 모형이다. 회귀모형은 선형과 비선형으로 나눌 수 있으며, 선형회귀모형은 종속변수 \(Y\)가 독립변수들의 선형 함수로 표현되는 것, 비선형회귀모형은 지수함수, 로그함수 등과 같이 종속변수 \(Y\)가 독립변수들의 비선형 함수로 표현되는 것을 말한다. 단순선형회귀모형은 독립변수가 한 개이고 종속변수와 선형관계가 있는 것을 말하며, 다중선형회귀모형은 독립변수가 두 개 이상이고 종속변수와 선형관계가 있는 것을 말한다.
추정해야할 회귀계수는 \(\beta_0\)(절편), \(\beta_1\)(기울기)이고, 절편보다는 기울기에 관심이 있다. 기울기를 알면 독립변수가 종속변수에 얼만큼 영향을 주는지 알 수 있다. 즉 \(X\)의 변화에 따라 \(Y\)의 변화량이 높으면, 독립변수가 종속변수를 설명하는 부분이 크다는 뜻이다. 반대로 \(X\)의 변화에 따라 \(Y\)의 변화량이 낮으면, 독립변수가 종속변수를 설명하는 부분은 큰 영향력이 없다는 뜻이다.
회귀계수 추정
오차제곱합을 최소화하는 방법(최소제곱법, Least Squared Method)으로 추정한다.
\[
min \left(\sum_{i} \varepsilon^2 _i \right)= \sum_{i=1}^{n} \left(y_i - \beta_0 - \beta_1 X_i \right)^2
\] - 각각 편미분을 통해서 \(\beta_0\), \(\beta_1\)을 추정하며, 최종적으로 추정된 식은 \(\hat{y}\)으로 표현한다.
자연과학에서는 실험을 통해서 자료를 수집하며, \(0.8\) 이상으로 높은 설명력을 보이며, 사회과학에서는 관찰을 통해서 자료를 수집하며, \(0.3\) 근처의 수치로 나타난다.
가정에 대한 검토
회귀모형설정에서 오차에 대한 정규성, 독립성, 등분산성을 가정한다.
추정된 회귀식으로부터 잔차(residual)를 계산할 수 있고, 잔차는 오차항을 추정하는데 사용할 수 있다.
\[
e_i = y_i - \hat{y_i}
\]
잔차를 이용하여 모형이 선형인지 적합성 검정을 할 수 있고, 오차항의 정규분포, 오차항의 등분산성 등을 확인할 수 있다.
오차항들은 서로 독립이어야 하므로 자기상관이 있는지 검토해야 한다. 더빈-왓슨(Durbin-Watson) 검정을 통해 하며, 다음 식의 \(d\)의 값이 \(0 \sim 4\)의 값을 가진다. \(2\)근방이면 자기 상관이 없는 것(독립)이고, \(2\) 미만이면 양의 자기상관, \(2\) 초과면 음의 자기상관을 갖는다.
\[
d = \dfrac{\sum\limits_{i=2}^{N}\left(e_i - e_{i-1}\right)^2}{\sum\limits_{i=1}^{N} e^2 _i}
\]
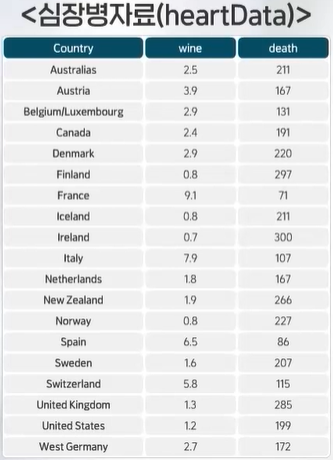
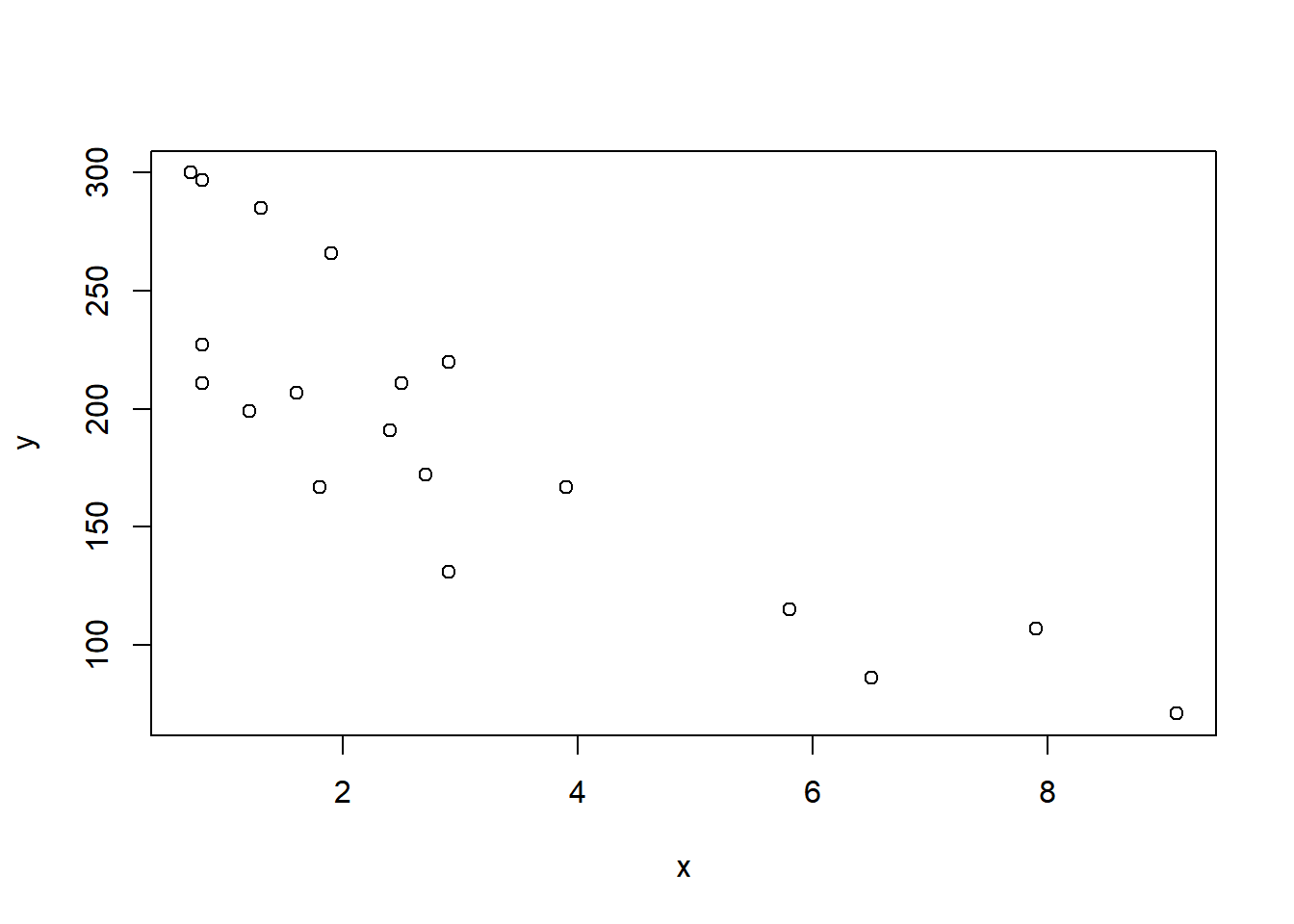
# scatter plotx = heartData$winey = heartData$deathplot(x, y) # 그래프 상 와인을 많이 마실수록 심장사망률이 낮아지고 있음
# correlation coefficientcor.test(x, y) # 강한 음의 상관관계가 존재하며, 즉 의미있는 음의 기울기가 나옴
Pearson's product-moment correlation
data: x and y
t = -6.4566, df = 17, p-value = 5.913e-06
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.9379588 -0.6296368
sample estimates:
cor
-0.8428127
# regression analysismodel =lm(y~x)summary(model) # hat y = 260.563 - 22.969 x, 포도주소비량은 심장병 사망에 영향을 미치며, 결정계수 값이 0.7103이므로 포도주 소비량이 심장병 사망에 대해 71% 정도 설명함.
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-62.95 -25.91 -12.35 26.97 55.52
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 260.563 13.835 18.833 7.97e-13 ***
x -22.969 3.557 -6.457 5.91e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 37.88 on 17 degrees of freedom
Multiple R-squared: 0.7103, Adjusted R-squared: 0.6933
F-statistic: 41.69 on 1 and 17 DF, p-value: 5.913e-06
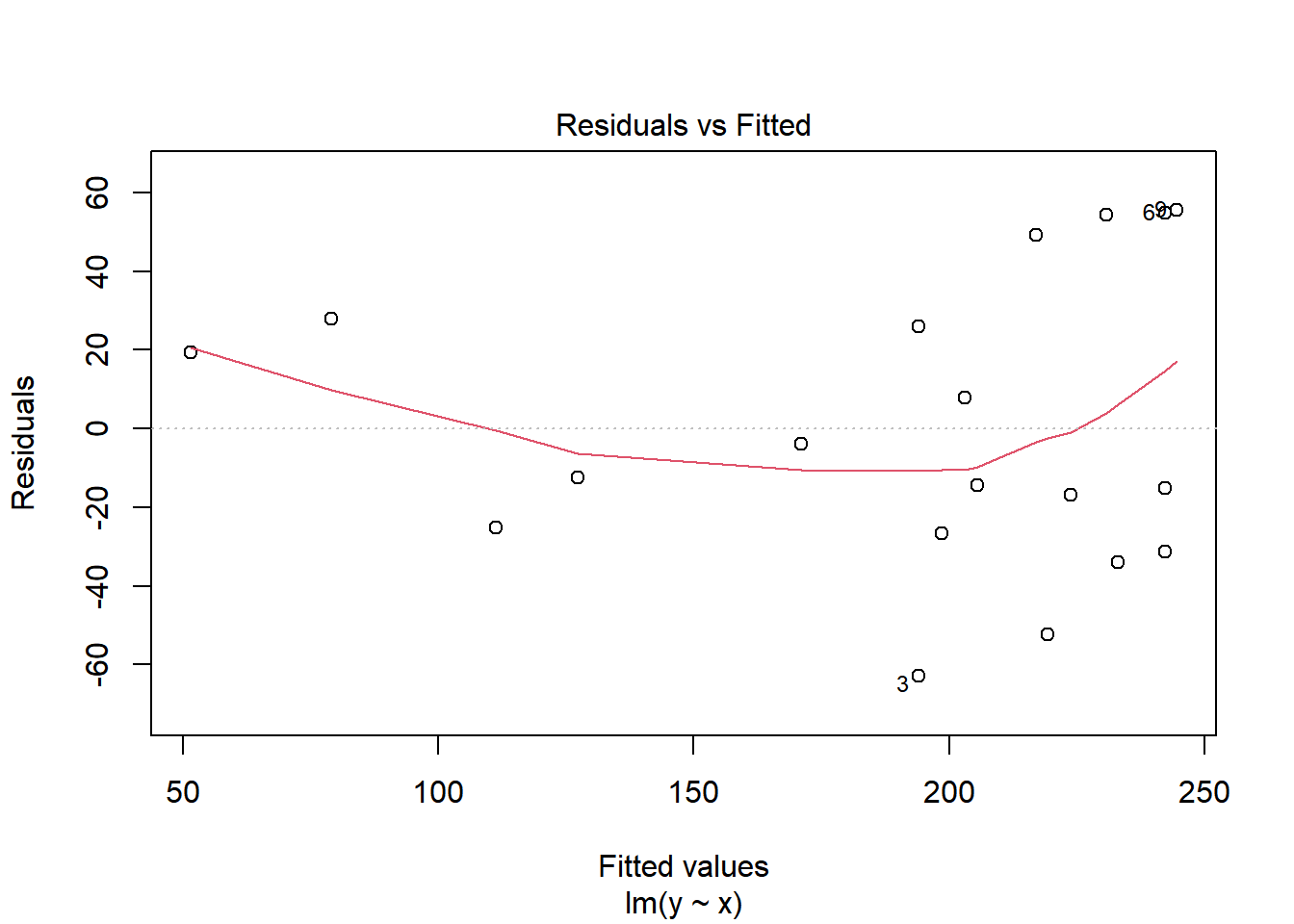
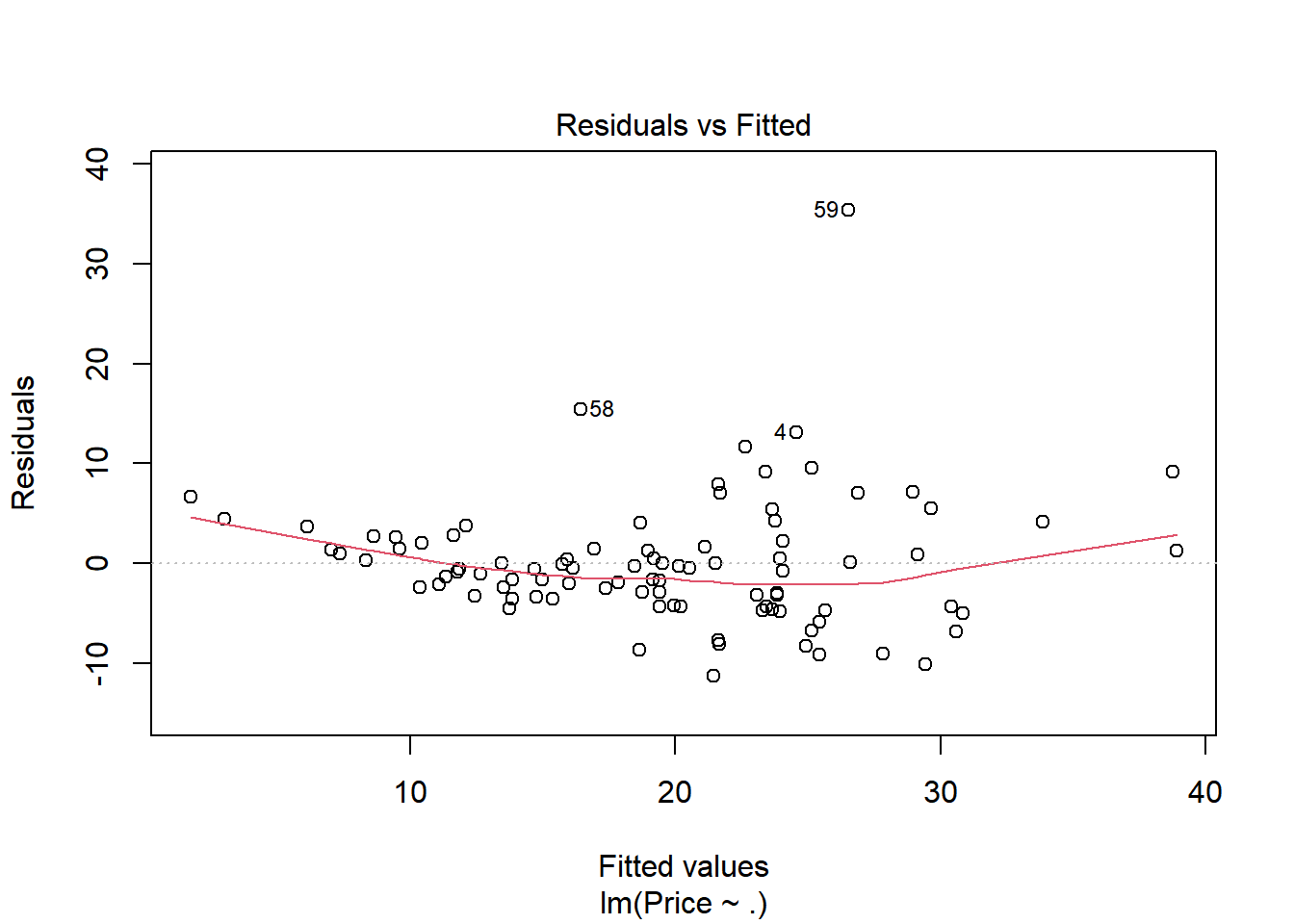
## normal, equal variance, independent(단순선형회귀 결과의 잔차를 통한 회귀진단)plot(model, 1) # linear, 모든 예측값에서 점선을 기준으로 잔차가 비슷하게 분포해야 모형이 선형성을 만족한다고 할 수 있음
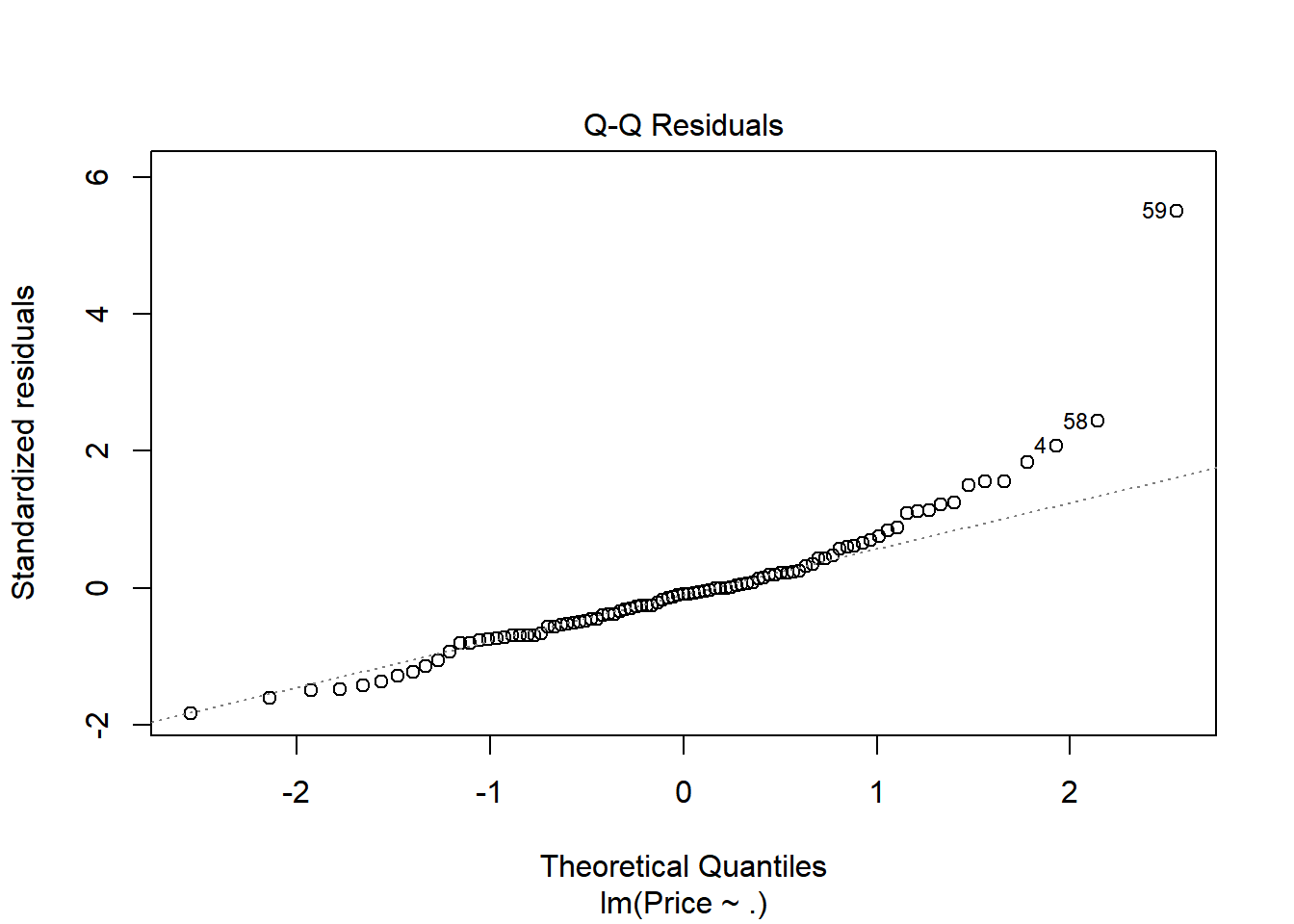
plot(model, 2) # normality, 직선 상에 점들이 놓이면 정규분포임
shapiro.test(model$residuals) # normality, 귀무가설이 정규분포를 따름, p값에 따라 귀무가설 채택
Shapiro-Wilk normality test
data: model$residuals
W = 0.93787, p-value = 0.2413
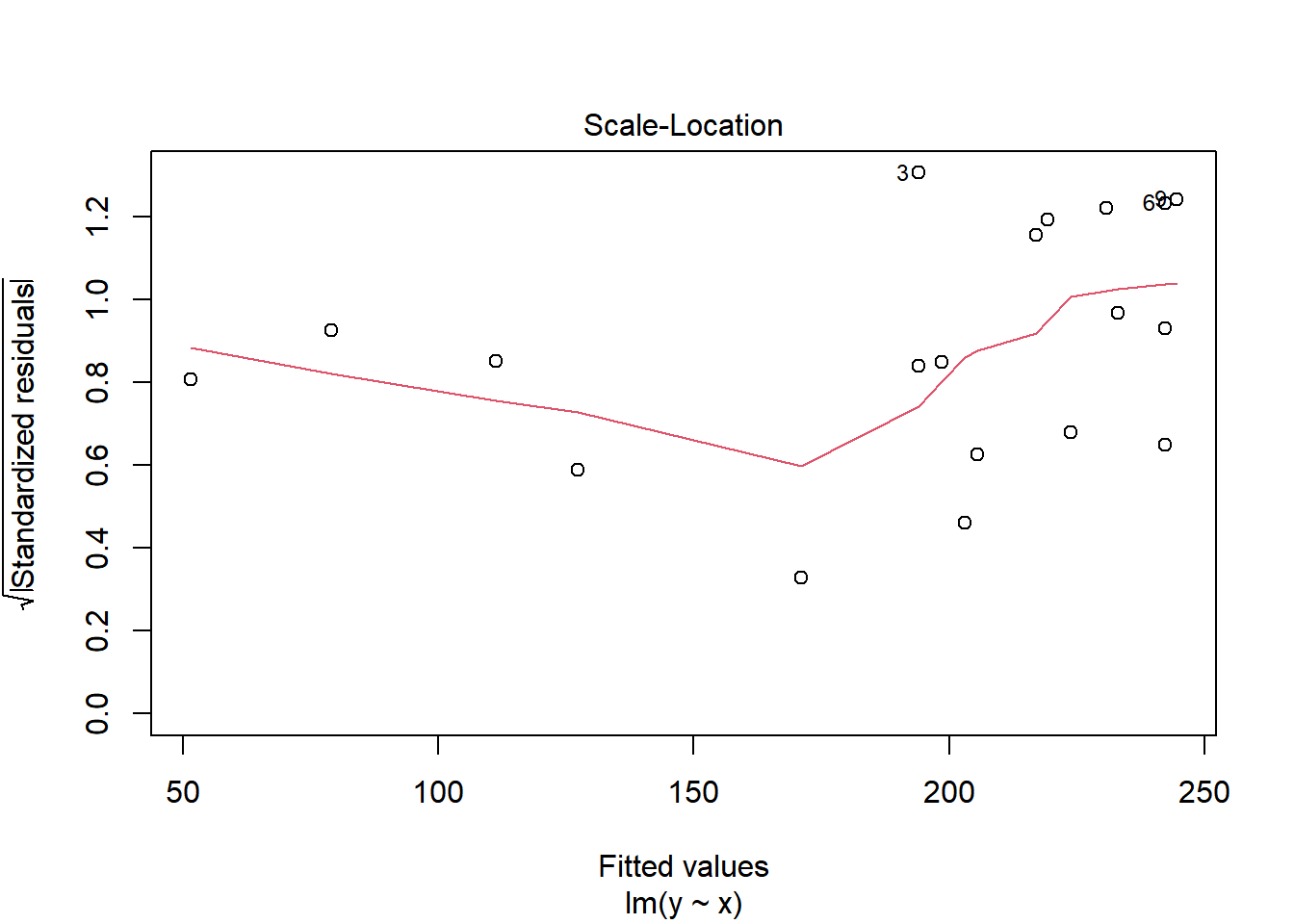
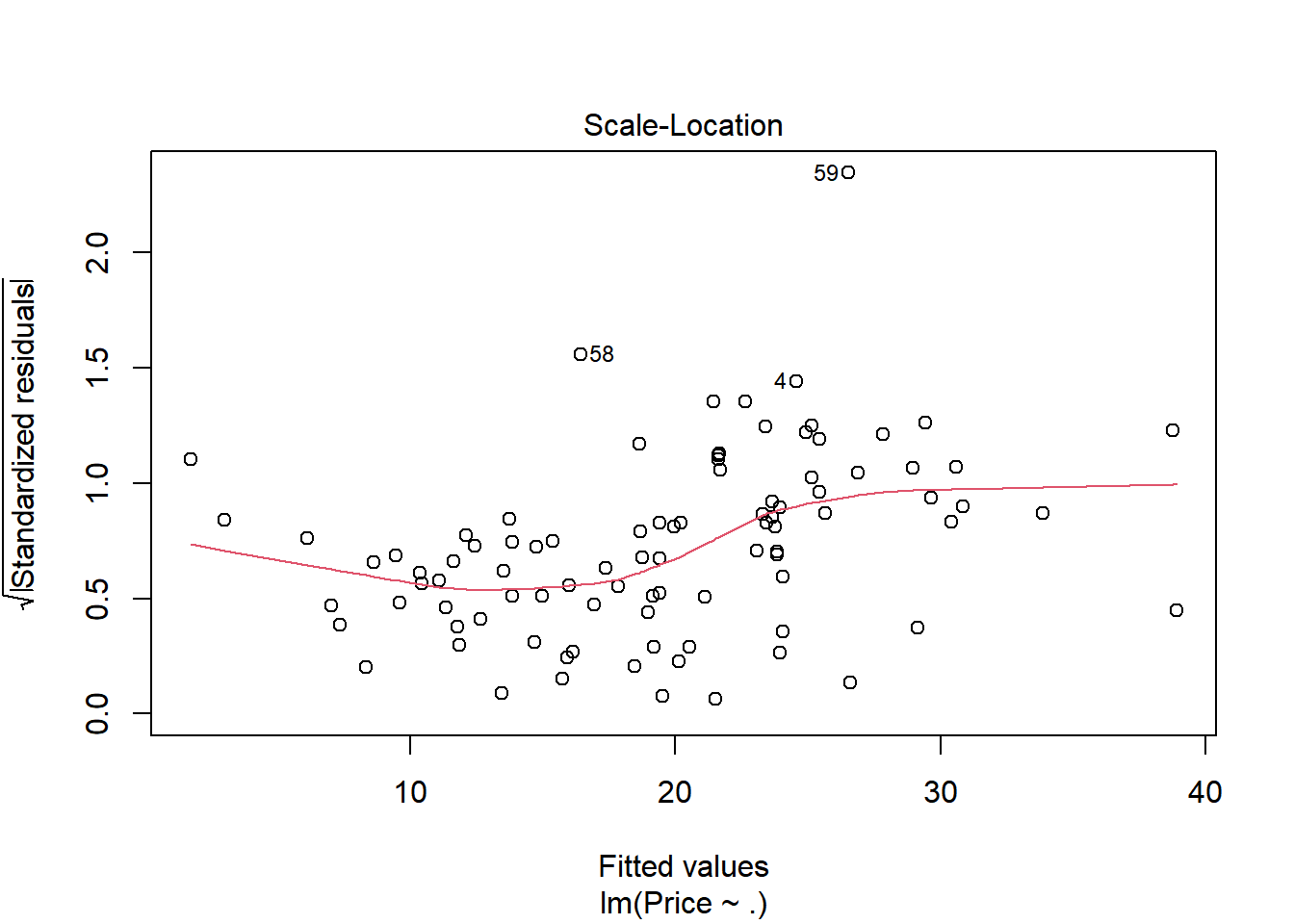
plot(model, 3) # equal variance, 빨간 실선이 수평선으로 나올수록 오차항의 등분산성 만족## Durbin-Watson test: Ho: errors are independent# install.packages('lmtest') # lmtest 패키지가 없으면 주석을 지우고 설치하기library(lmtest)
Warning: package 'lmtest' was built under R version 4.3.3
Loading required package: zoo
Attaching package: 'zoo'
The following objects are masked from 'package:base':
as.Date, as.Date.numeric
dwtest(model) # DW값이 2근방에 와야함.
Durbin-Watson test
data: model
DW = 2.2068, p-value = 0.7181
alternative hypothesis: true autocorrelation is greater than 0
다중선형회귀분석
다중선형회귀모형은 독립변수가 여러 개인 선형모형이다. 여러 독립변수들은 서로 독립이며, 독립변수의 숫자가 적을수록, 그리고 종속변수를 잘 설명할수록 좋은 모형이다.
Call:
lm(formula = Price ~ Weight + RPM + EngineSize, data = data)
Residuals:
Min 1Q Median 3Q Max
-10.511 -3.806 -0.300 1.447 35.255
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -51.793292 9.106309 -5.688 1.62e-07 ***
Weight 0.007271 0.002157 3.372 0.00111 **
RPM 0.007096 0.001363 5.208 1.22e-06 ***
EngineSize 4.305387 1.324961 3.249 0.00163 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.504 on 89 degrees of freedom
Multiple R-squared: 0.5614, Adjusted R-squared: 0.5467
F-statistic: 37.98 on 3 and 89 DF, p-value: 6.746e-16
광고비 및 설비투자와 매출액 연관성 비교 자료
다음 표는 광고비와 설비투자가 매출액에 어떤 영향을 미치는지 보여주고 있다.
광고비
5
6
7
8
9
11
12
13
14
15
설비투자
2
1.9
4
5.6
6.1
6.2
7
7.2
8
9
매출액
16
19
18
20
24
26
30
32
31
34
매출액(\(Y\))에 대한 광고비(\(X_{1}\))와 설비투자(\(X_{2}\))의 다중선형회귀모형을 구하시오.
x =matrix(c(5,6,7,8,9,11,12,13,14,15,2,1.9,4,5.6,6.1,6.2,7,7.2,8,9,16,19,18,20,24,26,30,32,31,34), nrow=10, ncol=3)colnames(x)=c("광고비","설비투자","매출액")x=data.frame(x)attach(x)x